论文阅读:PP-YOLOv2
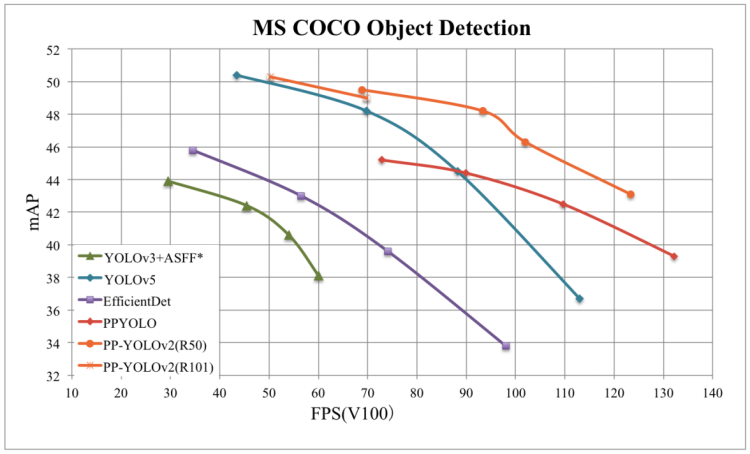
PP-YOLOv2是在PP-YOLOv1基础上进一步提高效率得到的,最后结果是性能进一步提高而推理时间几乎没有变化。PP-YOLOv2(Resnet50)的mAP从45.9%提升到49.5%(COCO2017测试集上),基于Resnet101的mAP达到了50.3%,在640*640输入下帧率为68.9FPS,经过TensorRT FP16精度的加速,最后帧率提升到106.5FPS。
1. 介绍
PP-YOLOv2和YOLOv5l和YOLOv4-CSP具有几乎相同的参数,但性能好一些。PP-YOLOv2的baseline是PP-YOLO,而PP-YOLO又是YOLO-v3的增强版本。
Github仓库:https://github.com/PaddlePaddle/PaddleDetection
Gitee镜像:https://gitee.com/paddlepaddle/PaddleDetection
pp yolov2.pdf
2. 回看PP-YOLO
2.1 预处理
- 模型权重初始化使用Beta(α,β)分布
- 图片使用随机颜色崩坏、随机扩充、随机裁剪、随机翻转等tricks
- 将图片RGB归一化
2.2 基线模型
在YOLO-v3上使用了10个提高性能但不损失效率的tricks,包括Deformable Conv,SSLD,CoordConv,DropBlock,SPP等。
2.3 训练策略
使用了SGD优化,使用了小batch(96张图片分8个GPU),学习率逐步升高….
3. PP-YOLOv2的改进
3.1 路径聚合网络(Path Aggregation Network)
在目标检测领域,探测不同尺度的目标是一个重要的挑战。在PP-YOLO里面使用了FPN(Feature Pyramid Network,特征金字塔网络)来组建自底向上的路径;此处,PP-YOLOv2采用了PAN的设计使用自顶向下的信息。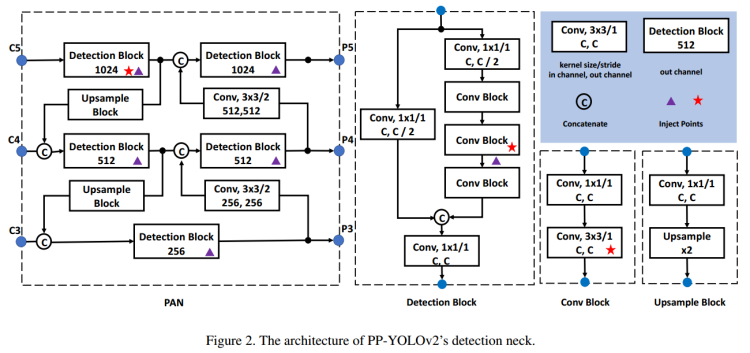
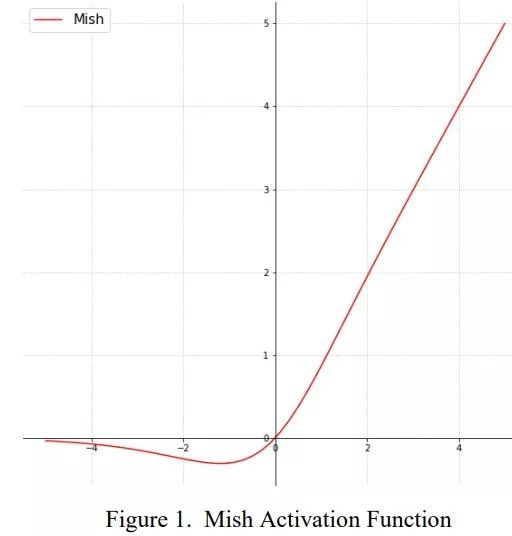
3.2 激活函数:Mish
Mish公式如下:
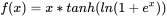
3.3 更大的输入尺寸
增大输入尺寸会扩大目标的区域,因此小尺度目标的信息会比以前更容易保存(我不理解!)
Increasing the input size enlarges the area of objects. Thus, information of the objects on a small scale will be preserved easier than before.
3.4 IoU感知分支
定义了IoU损失如下。感觉类似交叉熵,不过把输入p换成了σ(p)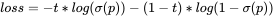
4. 实验
4.2 消融实验
他们还做了消融实验,A是基线模型,每一个创新点加上去mAP都有一些提升。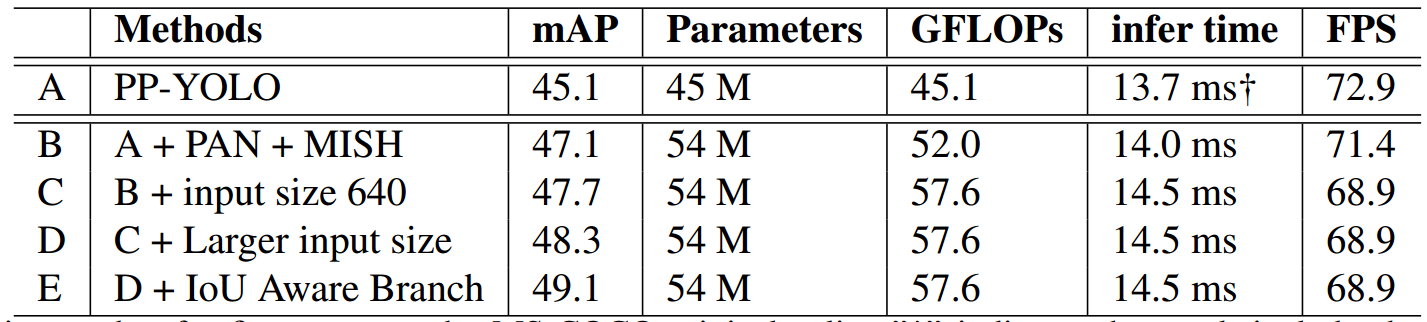
5. 没用的尝试
以下tricks尝试过,但没有带来性能提升:
- 余弦学习率衰减
- 骨干参数冻结
- SiLU激活函数
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏是不耍流氓的鼓励