论文阅读:wenet
Wenet是业内比较有名的语音识别网络,可以统一识别流式和非流式语音,并且是一个end2end网络。相比其他理论研究注重实用性,可以真实部署(咋感觉这么奇怪樂)
本文主要是wenet第一个版本的阅读笔记,对应论文地址
Abstract
- 主要工作:提出了WeNet,在单个模型中使用了双通道的U2来统一了流式&非流式的端到端语音识别。
a new two-pass approach named U2 is implemented to unify streaming and non-streaming end-to-end (E2E) speech recognition in a single model.
动机:跨越了研究与应用的鸿沟,提供了一种高效的方式在真实世界部署自动语音识别的方法(ASR, automatic speech recognition),这也是和其他开源e2e工具的区别。
方法:
- 网络架构:开发了一种混合连接时序分类(CTC)/注意力架构,transformer/conformer作为编码器,注意力解码器对编码器的假设重新评分
We develop a hybird connectionist temporal classification (CTC)/attention architecture with transformer or conformer as encoder and an attention decoder to rescore th CTC hypotheses.
- 流式/非流式统一:使用动态的基于块的注意力机制,这会允许自注意力关注任意长度的正确内容
结果:相对错误率降低了5.03%(AISHELL-1数据集,非流式,比标准的transformer)
WeNet
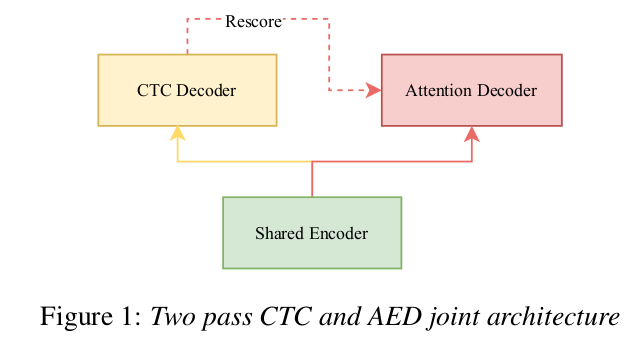
2.1 模型架构
Shared Encoder:由多个Transformer或Conformer组成,在适宜的延迟下考虑有限的上下文
CTC Decoder:由一系列线性层组成;根据shared encoder输出得到初步结果
Attention Decoder:由多个Transformer解析层组成;结合shared encoder的输出重新评估CTC输出,得到更精确结果
2.2.1 训练
定义了一个组合损失函数,将CTC和AED(attention based encoder-decoder)模块的损失加权相加
$$
L_{combined}(x,y)=\lambda L_{CTC}(x,y)+(1-\lambda)L_{AED}(x,y)
$$
对于流式/非流式统一,在流式识别中采用固定的chunk size=C将声音信号分割,这样就把流式识别问题转化成了chunk size为C的非流式问题。
2.2.2 解析(音频)
Wenet提供了4种基于python的音频解析模式,分别是以下四种:

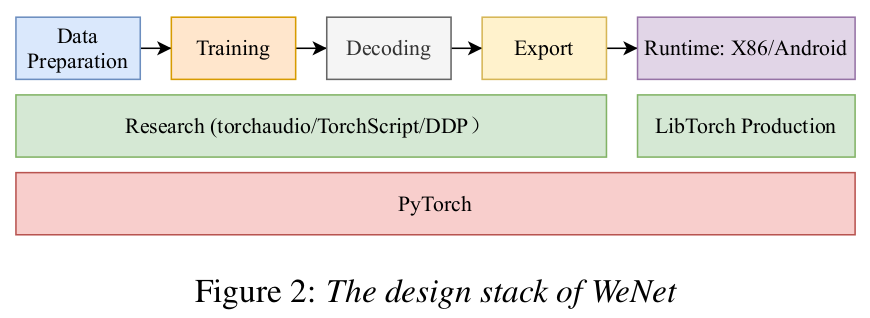
2.2 System Design
这就是wenet整个流程,主要流程是数据准备、训练、解码、导出、runtime,底层使用pytorch写的。
注意:这里的Decoding不是前面网络里面的解析器,而是Python based音频解析
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏是不耍流氓的鼓励