论文阅读:视频插帧算法-FILM
视频插帧算法(video frame interpolation, VFI)是一种用于提高视频帧率的算法。一些较早的方法通过计算光流进行运动补偿进行视频插帧(VFI),但光流计算实现复杂,后续计算全部依赖光流对其精度要求也高。随着神经网络的兴起,很多CNN-based视频插帧算法被提出来解决VFI任务。
阅读目标
本系列文章依然属于论文阅读部分,本文作为视频插帧VFI算法经典论文阅读的第一篇,阅读对象是FILM。
暂定阅读的模型和论文如下表,希望整体读完后对自己在论文写作和网络设计方面有一定启发。
| 索引 | 模型名 | 发表期刊 | 提出方 | 年份 |
|---|---|---|---|---|
| 1 | FILM | ECCV 2022 | 2022 | |
| 2 | Super SloMo | CVPR 2018 | Nvidia | 2018 |
| 3 | Quadratic Video Interpolation (QVI) | NeurIPS 2019 | 商汤科技 | 2019 |
| 4 | Depth-Aware Video Frame Interpolation (DAIN) | CVPR 2019 | 上海交大 | 2019 |
| 5 | Softmax Splatting (SS) | CVPR 2020 | 波兰州立大学 | 2020 |
| 6 | MEMC-Net | IEEE Transactions on Pattern Analysis and Machine Intelligence | 上海交大 | 2021 |
| 7 | RIFE | ECCV 2022 | 旷视&北大 | 2022 |
写作逻辑
2022 ECCV会议上,Google提出了FILM网络,该网络在视频插帧任务上完成度较高。
整篇文章创新点在于首创地解决了near-duplicate photos interpolation任务
- 提出了multi-scale shared feature extractor,解决了大尺度运动问题
- 采用了Gram matrix loss来度量感知损失,最后产出了高质量帧
- 引入了single unified network,解决了传统算法训练复杂的问题
Abstract
- 已完成工作(总):我们提出了一种FI算法,能合成图片间的慢动作
- 行业背景:近乎相同图片的插值是个有趣的应用,但是大尺度运动对现有方法造成挑战
- 已完成工作(细节):基于大小尺度的小大运动一致性假设,提出了共享参数的特征提取器;为了解决大尺度畸变,提出了GRAM Loss;为了简化训练,提出了联合单一网络(也就是e2e)代替光流计算
- 已获得结果:在数据集上与SOTA对比取得最优表现
1. Introduction
P1 重要概念界定:给出FI定义
P2 行业背景/应用场景:可以为电子照相插值获得视频,并揭示一些场景运动,最后获得更愉悦的场景
P3 同行工作:在小运动方面做得很好,但是较少关注大运动
P4,P5,P6 自己工作和同行工作对比,同行工作哪里做的不好,自己如何解决
P7 总结summary
2. Related Work
总:总结其他工作的共同点,提出自己工作的独创性。
分:从大尺度运动、图像质量、单步网络三个角度总结了其他插帧工作的不足和自己工作的创新点。
3. Method
FILM有3个主要步骤:共享参数特征提取(Feature Extraction)、尺度不可知的运动预测(Flow Estimation)、融合(Fusion)。
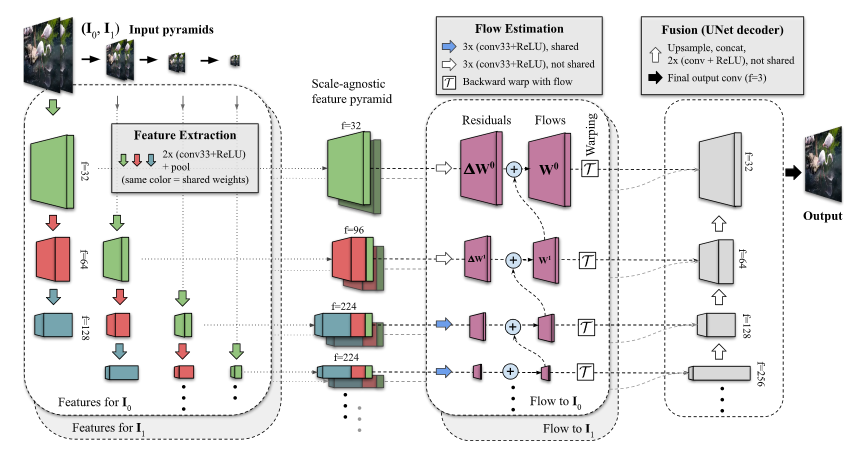
Feature Extraction
- 输入图像金字塔一共有7层(pyramid level),实际上就是上图中
Input pyramids,表示如下
$$
{I_0^l,I_1^l},l∈[1,7]
$$
- 对不同level输入图片提取多尺度特征,如上图Feature Extraction竖向的部分,表示如下
$$
f^{l,d}=H^d(I_0^l),d∈[1,4]
$$
Hd是a stack of convolutions, f是输入l level、d层的特征
- 拼接concat
Flow Estimation
we use them (前面提取器得出的F0和F1) to calculate a bi-directional motion at each pyramid level.
这里说的bi-directional motion指的是t→0和t→1运动,t是中间帧索引
这里和其他论文一样都是从coarsest level到细粒度,即l=7-> l=1。
- Warp张量递推式
当前W计算方式:下一level的W + (当前level帧0特征图、当前level帧1到t特征图)的非线性组合,也就是:粗粒度 + 细粒度。
此处是不是写的有问题,括号内应该是F1才对?
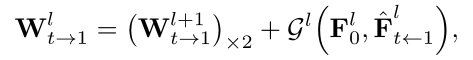
- 当前level帧t相对1特征图(估测)
计算方式:下一level的Warp张量2X上采样 + 当前level帧1特征图的bilinear resample
就是对当前level的F进行粗粒度的warp而已,所以是估测值,带入到上式得到准确warp矩阵。
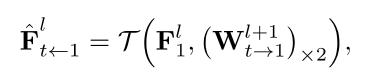
- 当前level帧t相对1特征图(输出)
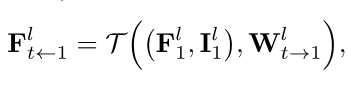
Fusion
UNet-like decoder,一笔带过
数据集
这个里面的motion magnitude如何计算的??
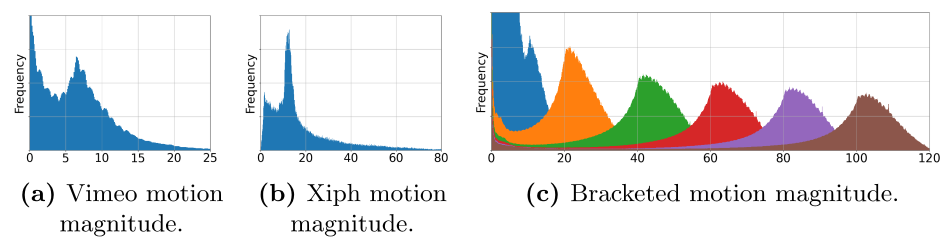
其他部分:略
视频解析
搬运自youtube
词句积累
| 英文 | 中文 |
|---|---|
| synthesizes an engaging slow-motion video | 合成一个连续的慢动作视频 |
| near-duplicate photos which often exhibit large scene motion | 展示了大尺度运动的几乎相同的照片 |
| pose challenges to | 给..带来挑战 |
| a feature extractor | 一个特征提取器 |
| relies on the intuition that | 基于…的假设 |
| large motion at fine scale | 小尺度的大运动 |
| small motion at coarser scales | 粗尺度的小运动 |
| boosts the number of available pixels | 增加了可用像素数 |
| inpaint wide disocclusions | 粉饰大尺度畸变 |
| synthesize crisp frames | 合成清晰帧 |
| measures the correlation differenc ebetwee nfeature | 度量相关性区别 |
| outperforms state-of-the-art methods | 比SOTAs好 |
| video synthesis | 视频合成 |
| synthesize intermediate images between a pair of input frames | 在一系列输入帧中合成中间图像 |
| with increasing reach | 随着影响力不断扩大的… |
| temporal up-sampling | 时序上采样 |
| increase refresh rate or create slow-motion videos | 增强刷新率或者创造慢动作视频 |
| with the advent of | 随着..…的问世 |
| the temporal spacing between near duplicates can be a second or more | 临近重复帧时间间隔可以是一秒钟甚至更多 |
| with commensurately | 同时 |
| consecutive video frames | 连续视频帧 |
| interpolation for large scene motion | 大尺度运动的插值 |
| CNN-based frame interpolation methods | 基于CNN的帧插值方法 |
| up-scale frame rate of videos | 上采样视频帧率 |
| perceptual loss | 感知损失 |
| Hd is a stack of convolutions | Hd是一堆卷积 |
| directly predict task oriented flow | 直接预测任务姿态流 |
参考文献
- FILM: Frame Interpolation for Large Motion (film-net.github.io)
- google-research/frame-interpolation: FILM: Frame Interpolation for Large Motion, In ECCV 2022. (github.com)
附件
- 预训练模型:源文件在作者谷歌云盘
- 论文视频:源文件在youtube
链接: https://pan.baidu.com/s/1TvH_7IZT12xSpOr6ARKwGg?pwd=m3zx
提取码: m3zx
复制这段内容后打开百度网盘手机App,操作更方便哦
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏是不耍流氓的鼓励