论文阅读:视频插帧算法Super-SloMo
Super SloMo是一个视频插帧模型,提出于2018年CVPR论文《Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation 》,提出机构是NVIDIA。
该模型是VFI领域一个重要的模型,在当时存在方法均为单帧插值时应用了多帧插值,并效果领先。
阅读目标
本文是阅读目标的第二篇,Super SloMo模型,阅读进度2/7。
| 索引 | 模型名 | 发表期刊 | 提出方 | 年份 |
|---|---|---|---|---|
| 1 | FILM | ECCV 2022 | 2022 | |
| 2 | Super SloMo | CVPR 2018 | Nvidia | 2018 |
| 3 | Quadratic Video Interpolation (QVI) | NeurIPS 2019 | 商汤科技 | 2019 |
| 4 | Depth-Aware Video Frame Interpolation (DAIN) | CVPR 2019 | 上海交大 | 2019 |
| 5 | Softmax Splatting (SS) | CVPR 2020 | 波兰州立大学 | 2020 |
| 6 | MEMC-Net | IEEE Transactions on Pattern Analysis and Machine Intelligence | 上海交大 | 2021 |
| 7 | RIFE | ECCV 2022 | 旷视&北大 | 2022 |
写作逻辑
Abstract
摘要是文章内容的汇总,主要包括行业背景、本文工作、本文结果。实际上这篇论文摘要就是这么写的,我从这三个角度来提炼摘要内容。
行业背景:视频插值是从两个给定的空间、时间连续的视频帧中生成一个或多个中间帧(定义)
目前大多数方法关注单帧插值,即在两帧中插入一个中间帧
本文工作:我们提出了一种端到端的神经网络用于可变长度多帧插值,包括了运动插值和遮挡推理
细节:使用了U-Net进行双向光流计算,然后使用另一个U-Net来完善光流并且预测软视图(soft-visibility maps),最后将两个输入帧扭曲(warp)并线性融合得到中间帧本文结果:消除伪影,在现存方法中中获得最好结果
1. Introduction
P1 应用场景:美好回忆发生时,你只用了标准帧率来录制视频…
P2 应用场景+别人工作:视频插帧很有研究价值,既可以生成平滑的视图转换,也可以应用在自监督学习中(引用别人工作:从未标记视频中获取光流信号)
P3 现有问题:由于时空都要连贯,所以多帧插值困难。
P4 别人工作:现有方法都是单帧插值,不能直接多帧插值。可以递归插值,但是至少有两个弊端:
- 递归插值无法并行化,并且插值错误也会传递
- 只能进行(2的指数次-1)插值
P5 本文工作:提出了变长度多帧插值方法(variable-length multi-frame interpolation method,这里的变长度应该指的是可以插任意多帧,对应递归插值弊端2)。结合现有问题和别人工作弊端谈自己网络结构和创新点。
P6 本文工作:训练设置
3. Proposed Approach
3.1 视频帧融合 Intermediate Frame Synthesis
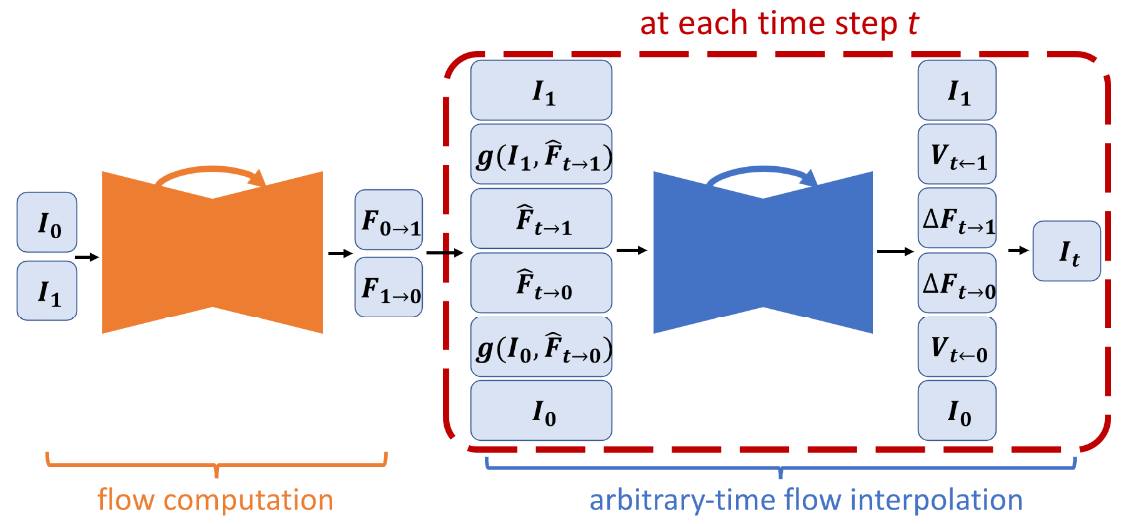
前文说到提出的方法是warp输入帧然后线性组合的,融合公式表述如下,g(·)代表反向补偿函数backward warping function,α0也是张量,由时序运动和遮挡推理决定,⊙代表元素尺度相乘:
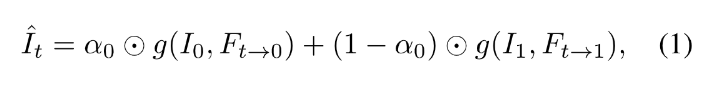
考虑到遮挡问题(occlusion problem),引入了视图visibility maps变量V,把上面的α0用V和t来表达,此处的Z为归一化因子,融合公式进一步可以如下表述:
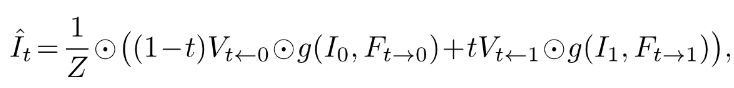
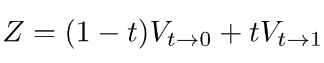
3.2 任意时间流插值 Arbitrary-time Flow Interpolation
以下面像素点为例:
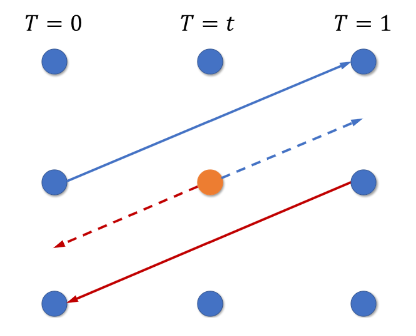
橙色点p从t到1的大致光流可以使用0到1的光流来按比例截取,大致光流计算如下:
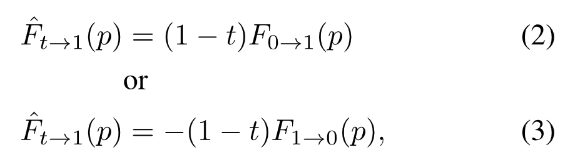
和RGB图像融合的时序连续相近,我们能使用双向光流预估t时刻到0/1的光流:
这里不明白,为啥是二阶的呢?
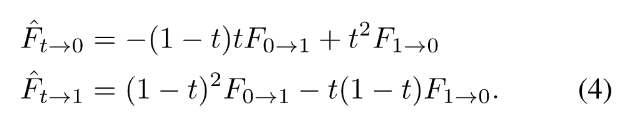
按照这种方法计算出来的光流可视化如下,第2行的是大致光流,第3行的是refined光流。

为了处理遮挡关系,作者使用了流插值网络flow interpolation CNN预测了从t到0和从1到t的两种视图掩膜V。两种掩膜满足以下约束关系,否则网络训练会发散。
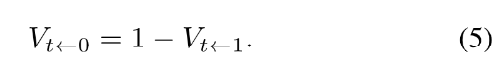
整个网络的架构如下:
4. Experiments
视频解析
这是论文第一作者在CVPR 2018 spotlights上的分享,时长4分钟。国内有人搬运到B站了,这里直接分享。
词句积累
| Given two consecutive frames | 给定两个连续帧 |
|---|---|
| intermediate frame(s) | 中间帧 |
| form both spatially and temporally coherent video sequences | 形成空间和时间连续的视频序列 |
| motion interpretation and occlusion reasoning | 运动插值和遮挡推理 |
| bi-directional optical flow | 双向光流 |
| refine the approximated flow | 完善大致光流 |
| we exclude the contribution of occluded pixels to the interpolated intermediate frame to avoid artifacts | 我们将被遮挡像素对插值的作用排除以避免伪影 |
| we use 1,132 240-fps video clips | 我们使用了1132个240fps的视频段 |
| demonstrate that our approach performs consistently better than existing methods | 证明了我们的方法总是比现有方法表现好 |
| professional high-speed cameras are still required for higher frame rates | 专业的高速相机仍然因更高帧率而被需要 |
| it is of great interest to generate high-quality slow-motion video from existing videos | 从现有视频产生高质量慢动作视频是有研究价值的 |
| generate smooth view transitions | 生成平滑的视图转换 |
| It is challenging to generate multiple intermediate video frames because the frames have to be coherent, both spatially and temporally. | 多帧插值有挑战性,因为时空都要连续。 |
| Existing methods mainly focus on single-frame video interpolation and have achieved impressive performance for this problem setup. | 现有方法主要关注单帧插值,并在此问题设置下取得了令人印象深刻的结果 |
| it is an appealing idea to | xx是一个很有吸引力的想法 |
| recursive single-frame interpolation | 递归单帧插值 |
| interpolate a frame at any arbitrary time step between two frames | 在两帧见任意时间插值一帧 |
参考文献
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏是不耍流氓的鼓励