论文阅读:ConvTransformer A Convolutional Transformer Network for Video Frame Synthesis
本文于 546 天之前发表,文中内容可能已经过时。
这篇文章使用了Transformer对图像进行了帧合成操作,文章链接如下:
ConvTransformer: A Convolutional Transformer Network for Video Frame Synthesis
放上划过重点的论文文件:ConvTransformer
Abstract & Introduction
CNNs在视频帧合成时因为物体变形和移动、环境光改变、相机视角的移动,表现不佳。本文提出了ConvTransformer网络,核心组成要素(core ingredient)是attention layer & multi-head convolutional self-attention,这些要素可以学习视频中帧的顺序依赖。经过实验,这个模型比ConvLSTM模型表现要好。
Related Works
VFI
先说视频帧融合问题是长期存在的,具有挑战性和内在ill-posed的一个问题,因为自然图片和视频是多模态的。Video frame synthesis is a longstanding low-level computer vision problem, which is very challenging and inherently ill-posed since the multi-modal distribution of natural images and videos.
传统使用的是光流法(optical flow),但是optical flow对视频中的motion和光变十分敏感。
一些基于深度神经网络的算法替代了光流法,称为optical based methods。[18]训练了一个通用CNN来直接合成中间帧,但有时会导致运动模糊;[17]提出了一种3D光流网络,但是面对大尺度运动仍然力不从心;[20,21]将帧插值认为是局部卷积问题,提出了一种CNN对每个像素点都生成空间适应的卷积核,效果不错,但计算量大(suffer from heavy computation),而且面临着同样的对运动敏感的问题。
如今,针对VFI的包括了运动估计和运动补偿的子模块模型被提出,称为warping based methods。虽然warping based methods不仅获得了好的插值结果并有无监督运动估计的光明前景,these warping based deep models are mainly developed based on two consecutive frames for frame interpolation, while the higher-order motion information of video frame sequence is ignored and not be well exploited.
不同于warping based methods,Vilegas et al. 提出了一种ConvLSTM based method MC-Net for extrapolation方法,但是这种方法在两帧有长距离位移时不能建立有效的关联,且由于递归模型导致计算量大,和optical based methods相比表现也不佳。
Transformer
Transformer是一种为了学习长范围的序列关系设计的一种新架构,开始成功应用于NLP任务如机器翻译、语音识别中。
具体而言,Zihang Dai et al. [8] 为了去除编码长度限制,在模型最后一部分采取了self-attention层建立各部分之间的联系,同时相对位置编码也被包含在他们的工作中。
Wu et al. [33] 减少了Transformer中的channel数,他们认为传统Transformer中有冗余信息,于是introduce了Long-Short Range Attention (LARA)来减少内存占用。
近期, Nicolas et al. 拓展了Transformer用于目标检测并且提出了DETR算法,并在COCO数据集上取得了和Faster RCNN相媲美的结果。DETR算法将二维分解为一维,通过self-attention替代了传统卷积的感受野。但DERT也不能应用于VFI领域,因为VFI和时间、空间高度相关。
Convolutional Transformer Architecture
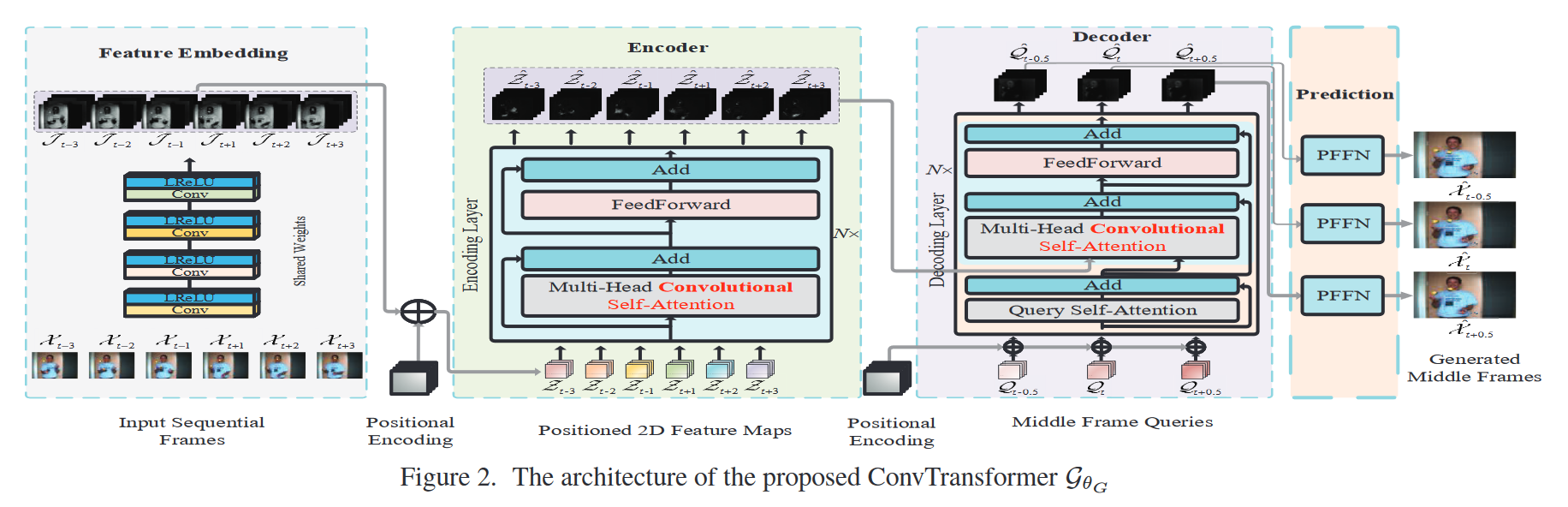
Algorithm Review
输入
$$
X={X_0,X_1,…,X_n}\in R^{H×W×C}
$$
输出
$$
X={X_{i+t_0},X_{i+t_1},…,X_{i+t_k}},t_k\in [0,1]
$$
首先,特征嵌入模块嵌入了所有输入视频帧,然后生成对应的特征图feature map。
随后,特征图feature map与位置图positioned map相加得到positioned feature map用于位置标识。
接下来,positioned feature map输入到encoder中建立长范围的序列依赖关系,得到编码后的高级特征图high-level feature map。
再后面,high-level feature map和positioned frame queries同时被传入Decoder中,然后对query frames和 input sequential video frames之间的顺序依赖性进行解码。
最后,得到decoded feature maps,输入到Synthesis Feed-Forward Networks (SFFN)中得到interpolated frames。
Feature Embedding
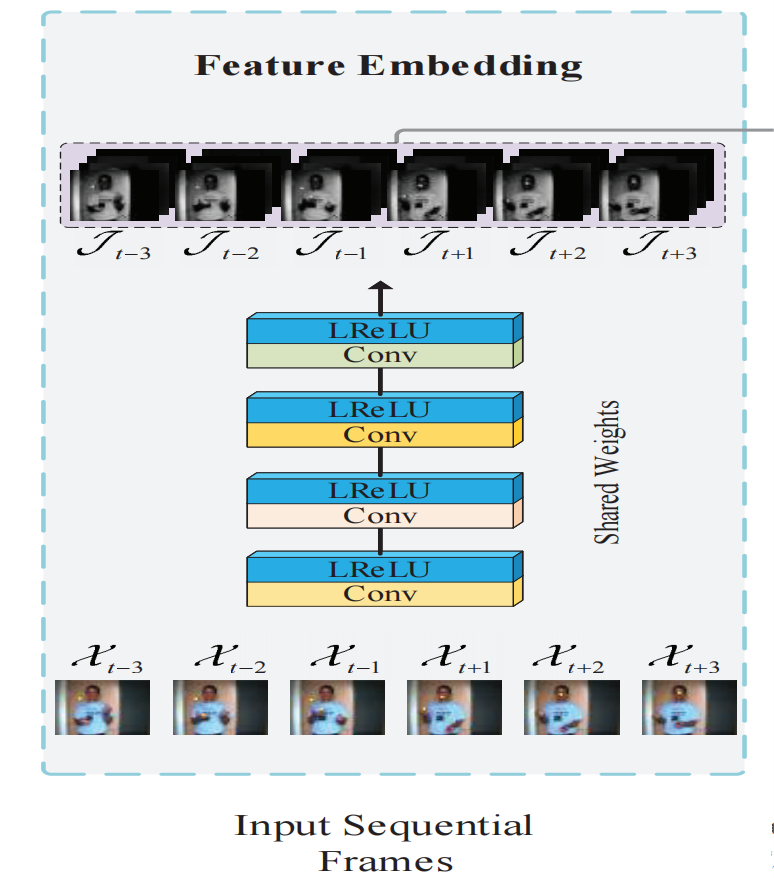
Feature Embedding模块采用了一个共享的卷积模块,包含了4个LeakyRelu激活的卷积,提取得到了Feature map。
Positional Encoding
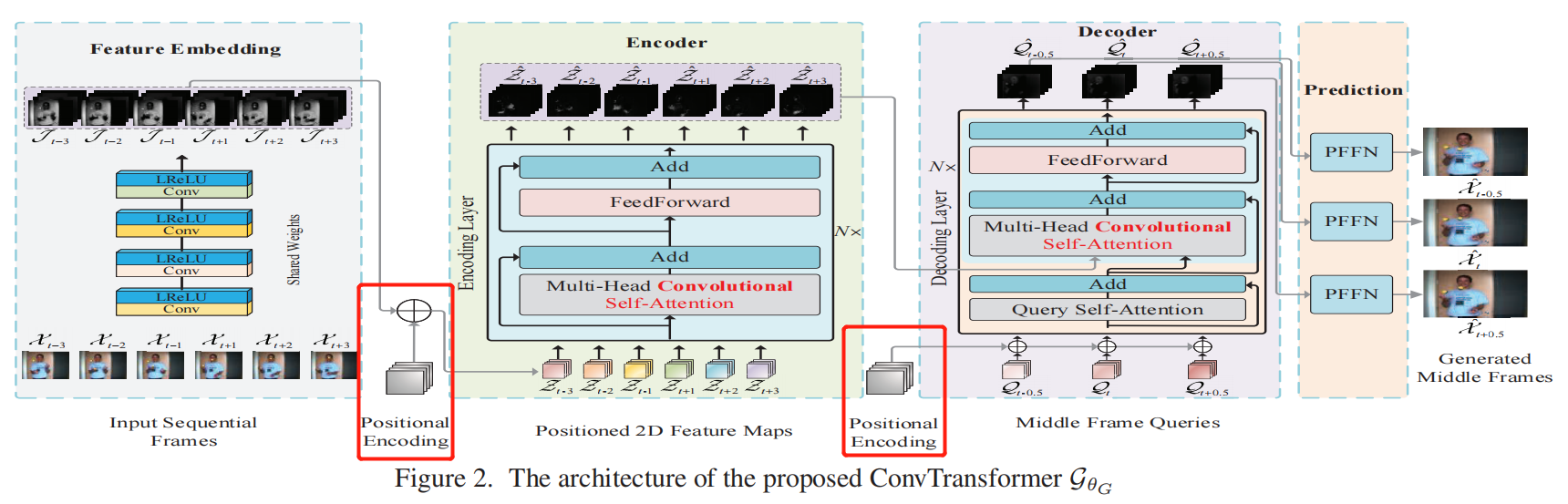
与原始面向向量的Transformer不同的是,此处的positional encodings是一个3D Tensor,与frame feature map有相同的维度,因此两者可以求和。公式如下:
$$
PosMap_{(p,(i,j,2k))}=sin(n/10000^{2k/d_{model}})\\
PosMap_{(p,(i,j,2k+1))}=cos(n/10000^{2k/d_{model}})
$$
此处,p代表position token,(i,j,2k)代表特征图上的空间位置,n代表输入的序列数量,$d_{model}$代表模型feature map的通道数(?)。
Encoder & Decoder
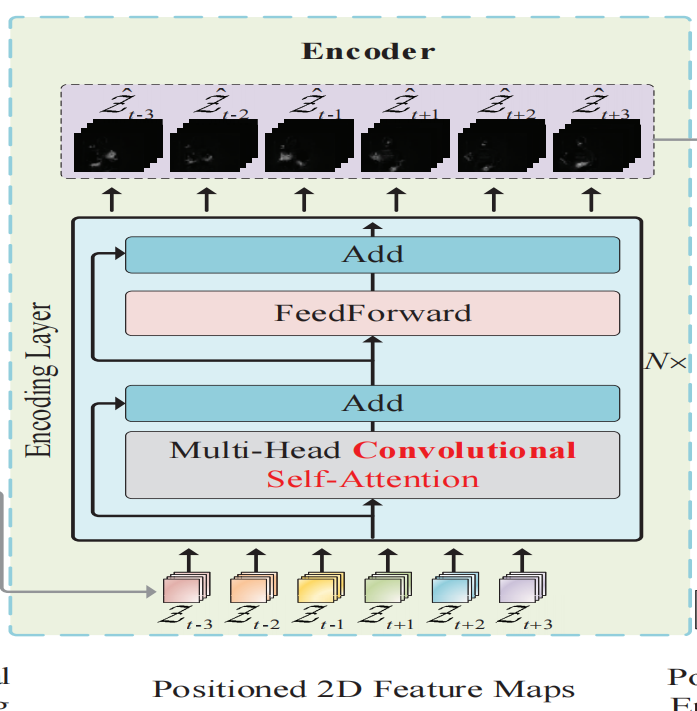
Encoder模块接收positioned feature map(表示为图中的${Z_t}$序列),the encoder is modeled as a stack of N identical layers,每一个stack由两个子层组成:多头卷积子注意力层、简单的2D卷积前馈层。模型中所有的子层都会采用相同维度的输出$d_{models}=32$
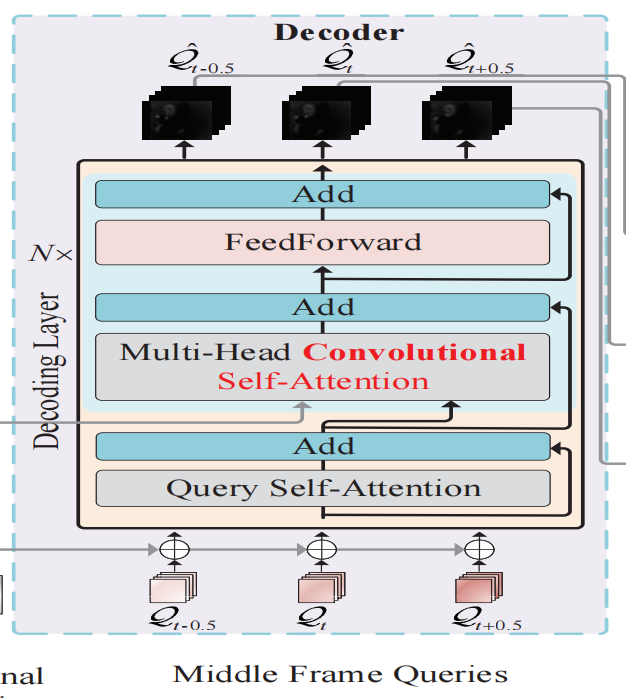
Decoder模块也是composed of a stack of N identical layers,每个stack包含了3个子层,除了Encoder中的两个子层,还插入了一个称为查询自注意(query self-attention)的附加层,以对输出帧查询执行卷积自注意。
Multi-Head Convolutional Self-Attention
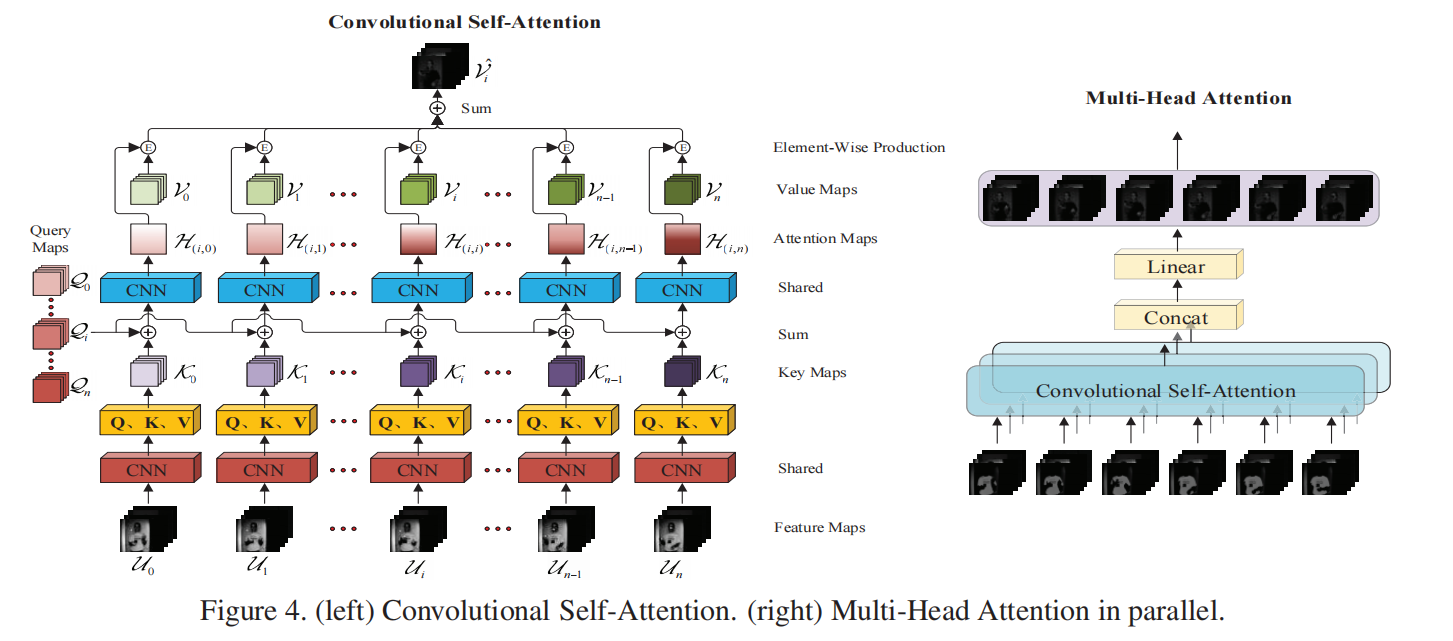
整个文章的灵魂,最重要的创新点!可以看到Convolution Self-Attention是使用一个CNN得到Q、K、V三个值(shape为H×W×3);将所有的K值加上Qi(第i个输入的查询矩阵)再经过CNN得到H(i,j),即key值j对输入i的attention map;当0<=j<n的H(i,j)全部计算出来,就有了其集合$H(i)={H(i,1), H(i,2), · · ·, H(i,n)}$ ,在第3维度上取softmax;将所有输入的H和V对应相加,再将结果相加,输出得到第i个输入的convolutional self-attention;公式表达如下:
$$
Q_i,K_i,V_i=CNN_1(U_i),Q,K,V\in R^{H×W×3}\\
H(i,j)=CNN_2(Q_t,K_j),H\in R^{H×W×1}\\
H(i)=Softmax({H(i,1), H(i,2), · · ·, H(i,n)})_d,d=3\\
V_i=sum(V_j+H(i,j))
$$
使用多个这样的Conv Self-Attention Block并行,就可以得到每一个输入的self-attention矩阵。
Synthesis Feed-Forward Network
没啥好说的,是一个unet类型的结构。
In order to synthesize the fifinal photo realistic video frames, we construct a frame synthesis feed-forward network, which consists of 2 cascaded sub-networks built upon a U-Net-like structure.
参考资料
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏是不耍流氓的鼓励