论文阅读:Vision Transformer with Progressive Sampling
本文于 521 天之前发表,文中内容可能已经过时。
PS-ViT是一个分类网络,发表于ICCV 2021上,特点是在ViT的基础上加入Progressive Sampling,获得更准确的结果。
Abstract & Introduction
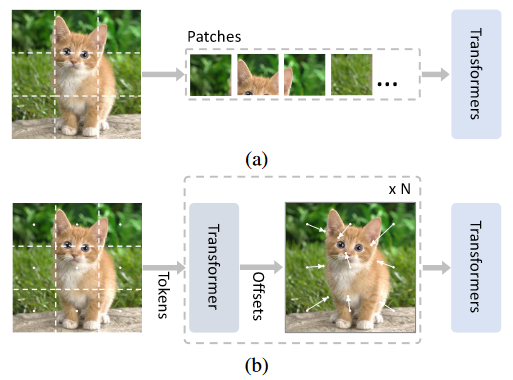
Transformer的复杂度和输入序列的长度的平方成正比,因此ViT会将图片分为几个patch展开为1维向量输入Transformer进行计算,但是这种朴素的token化方法割裂了patch之间的自然结构,并且将网格分配在不感兴趣的地方例如背景,此外还引入了干扰信号。(However, such naive tokenization could destruct object structures, assign grids to uninterested regions such as background, and introduce interference signals.)
为了解决上述问题,我们提出了一种迭代渐进的采样策略来定位判别区域。To mitigate the above issues, in this paper, we propose an iterative and progressive sampling strategy to locate discriminative regions.
每一次迭代,当前采样步的嵌入会被送到Transformer中的编码器中,然后一组采样偏移将会被预测得出,以此来更新下一步采样的位置。At each iteration, embeddings of the current sampling step are fed into a transformer encoder layer, and a group of sampling offsets is predicted to update the sampling locations for the next step.
Methodology
这部分将介绍PS策略的具体实现,PS-ViT网络的总体架构,最后将阐述(elaborate)网络的细节。
Progressive Sampling
渐进式采样的架构如下图所示,输入为$F\in R^{C,H,W}$,输出为Token的序列$T_N\in R^{C*(n*n)}$,
根据采样矩阵$p_t$在F上轴向采样得到$T’_i,i\in[0,n^2]$,
$T’i$和位置编码$P_t$,$T{t-1}$相加,
输入到Transformer Encoder得到编码后的$T_t$,
$T_t$一方面输出,一方面经过FC Layer得到新的采样矩阵$p_{t+1}$。
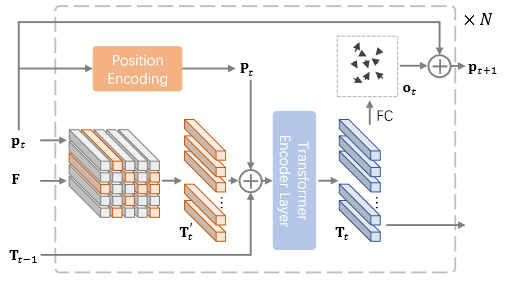
此处的(nn)表示采样的数量,N表示迭代的次数。下一次的采样位置等于当前采样位置与偏置相加:
$$
p_{t+1}=p_t+o_t,t\in [1,2,…,N-1]
$$
$p_t$和$o_t$都在空间$R_{2(n*n)}$上,在第一次迭代的时候$p_1$初始化为规则间隔的样子。
用公式来表示,一目了然:
$$
T’_t=F(p_t)\\
P_t=W_tp_t\\
X_t=T’t㊉P_t㊉T{t-1}\\
T_t=Transformer(X_t),t\in[1,…,N]\\
o_t=M_tT_t,t\in[1,…,N-1]
$$
上面的$M_t$是一种可学习的线性变换(应该是数层全连接层)。
Overall architecture
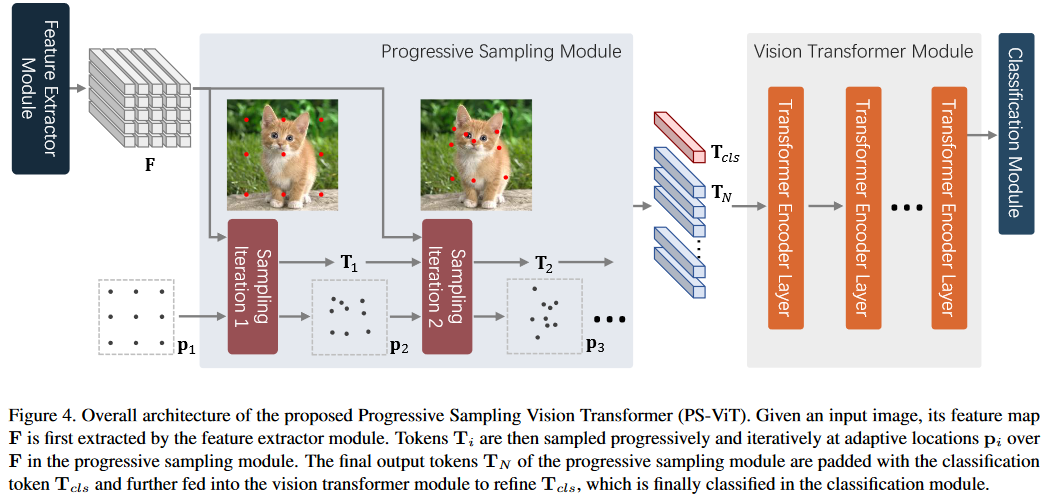
PS-ViT的总体架构如下,总共有4个部分组成:(1) Feature Extraction; (2) Progressive Sampling; (3) Vision Transformer; (4) Classification Module
参考文献
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏是不耍流氓的鼓励