论文阅读:Learning Texture Transformer Network for Image Super-Resolution
本文于 544 天之前发表,文中内容可能已经过时。
CVPR 2020论文,提出了TTSR(Texture Transformer Network for Image Super-Resolution)网络,使用Transformer对图像超分重建。
论文地址:Learning-Texture-Transformer-Network-for-Image-Super-Resolution
划过重点版本:Learning-Texture-Transformer-Network-for-Image-Super-Resolution
1. Abstract & Introduction
近来的研究都将HR Images作为reference(Ref),在TTSR中,将LR和Ref分别作为Transformer中的queries和keys。TTSR包含了4个紧密相关的部分:纹理提取器DNN( learnable texture extractor, LTE),相关性嵌入模块(a relevance embedding module, RE),纹理传输的硬注意力模块(a hard-attention module for texture transfer, HA),纹理合成的软注意力模块(a soft-attention module for texture synthesis, SA)。
此外,还提出了 a cross-scale feature integration module to stack the texture transformer,用于学习不同比例下的特征来得到更有力的特征表示。
2. Related Work
2.1 Single Image Super Resolution
Models: SRCNN, VDSR, DRCN, EDSR, SRGAN, …
Loss Function: MSE, MAE, perceptual loss(recent years), Gram matrix based texture matching
loss, ..
2.2 Reference-based Image Super-Resolution
RefSR可以从Ref image获得更加准确的细节,这可以通过image aligning或者patch matching(搜索合适的Reference Information)造成。
Image aligning缺点:依赖于对齐质量,且对齐方法如光流法等是耗时的。
Patch matching缺点:However, SRNTT ignores the relevance between original and swapped features and feeds all the swapped features equally into the main network. (?)
3. Approach
3.1 Texture Transformer
Texture Transformer包含4个部分,LTE,RE,HA,SA,结构如图所示:
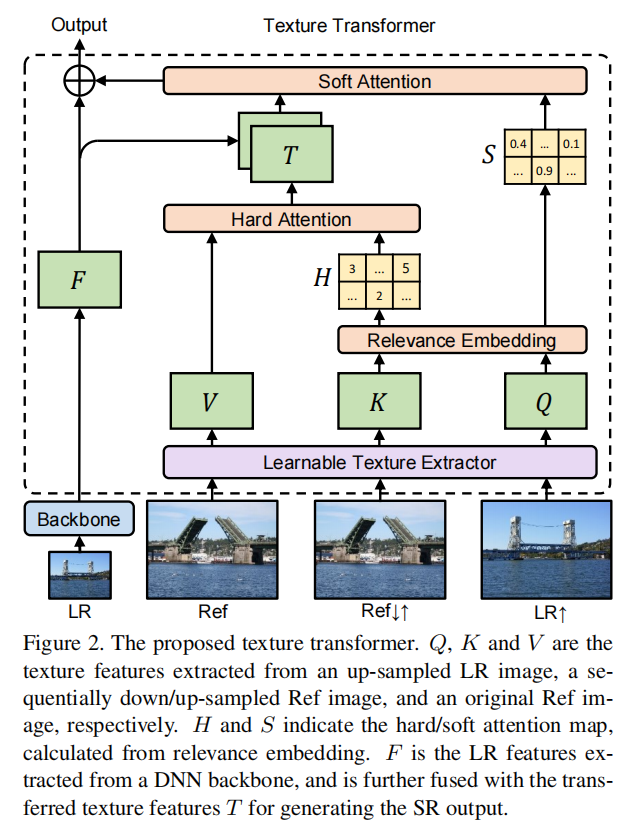
输入为Backbone(LR), Ref, Ref↓↑, LR↑,这里的↓↑分别代表使用Bicubic进行下、上插值,之所以对Ref先↓后↑是因为需要保持Ref↓↑与LR↑的域一致性(which is domain-consistent with LR↑)然后通过LTE得到K和Q;输出为合成的特征图(synthesized feature map)。
learnable texture extractor(LTE)
$$
Q=LTE(LR↑),\\
K=LTE(Ref↓↑),\\
V=LTE(Ref),
$$relevance embedding module(RE)
Relevance embedding aims to embed the relevance between the LR and Ref image by estimating the similarity between Q and K.
将Q/K输出的结果patch为小块,相关性r即可由qi和ki通过标准化内积计算出来:
$$
q_i,(i \in [1, H_{LR}×W_{LR}])\\
k_j,(j \in [1, H_{Ref}×W_{Ref}])\\
r_{i,j}=<\frac{q_i}{||q_i||},\frac{k_i}{||k_i||}>
$$hard-attention module for feature transfer(HA)
这一部分是将Ref的feature转移到当前图片的feature map中。传统方法是对不同的qi求V的加权和,但是这一操作可能会因为缺少Ref的feature导致模糊,所以我们在HA中仅仅将每个qi对应最相关的V值迁移出来。
具体来说,先由前述的ri,j计算hard-attention map H
$$
h_i=\mathop{argmax}\limits_{j}r_{i,j}
$$
上述argmax函数是当ri,j最大时,返回对应的自变量,文中应该就是j,即qi确定时,对应最相关的kj存储在hi中。(原文: The value of hi can be regarded as a hard index, which represents the most relevant position in the Ref image to the i-th position in the LR image.)为了获得tranferred HR texture features T,我们将拾取对应的V值到矩阵T中:
$$
t_i=v_{h_i}
$$
因此,图中的T代表从Ref中迁移的最相关的对应纹理特征。soft-attention module for feature synthesis(SA)
到了这一步,我们有了Ref的特征迁移矩阵T,LR的特征图F,本模块提出了一个soft-attention来合成特征。
Soft-attention map的矩阵S可由相关性ri,j计算得出:
$$
s_i=\mathop{max}\limits_{j}r_{i,j}
$$
最后的特征图有下面计算得出:
$$
F_{out}=F+Conv(Concat(F,T))⊙S
$$
⊙代表元素对应相乘。
3.2 Cross-Scale Feature Integration
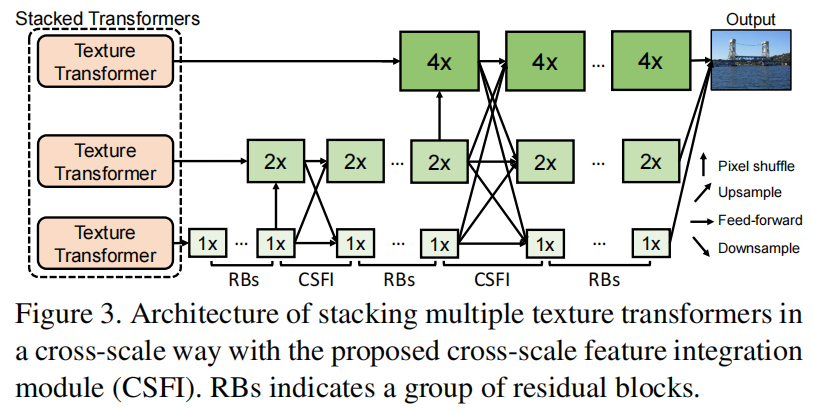
使用上面提出的Texture Transformer堆叠,分别由1x/2x/4x混合,得到output。(套娃也可以这么6,学到了)
3.3 Loss Function
本文的loss function包括Reconstruction loss,Adversarial loss,Perceptual loss三大块,总体的损失函数为三者的线性和,表示如下:
$$
L_{overall} = λ_{rec}L_{rec} + λ_{adv}L_{adv} + λ_{per}L_{per}
$$
好的表述
Image super-resolution aims to recover natural and realistic textures for a high-resolution image from its degraded low-resolution counterpart.(从其退化的低分辨率图片)
The research on image SR is usually conducted on two paradigms, including single image super-resolution (SISR), and reference-based image super-resolution (RefSR).(范式)
Although GANs…, the resultant hallucinations and artifacts caused by GANs further pose grand challenges to image SR tasks.(幻觉;伪影)
SOTA(State-of-the-Art)
First, … | Second, … | More specifically, … | Finally, …
To the best of our knowledge, … (据我们所知,…)
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏是不耍流氓的鼓励