目标检测--YOLO的原理步骤学习笔记
本文于 1232 天之前发表,文中内容可能已经过时。
YOLO (You Only Look Once)是一种端到端学习的目标检测算法,已经更新迭代了好几代,因为响应迅速、抓取准确等优点被广泛使用。本文以吴恩达深度学习作业(提取码:cw7y)中的无人驾驶路测场景为例子整理。
第一步:网格化/训练网络
将训练图片(这里的shape是608,608,3)划分为19x19的网格,每一个网格有两个属性——锚框(anchor box)和类别(classes)。每个网格对应有5个锚框,80个类别。
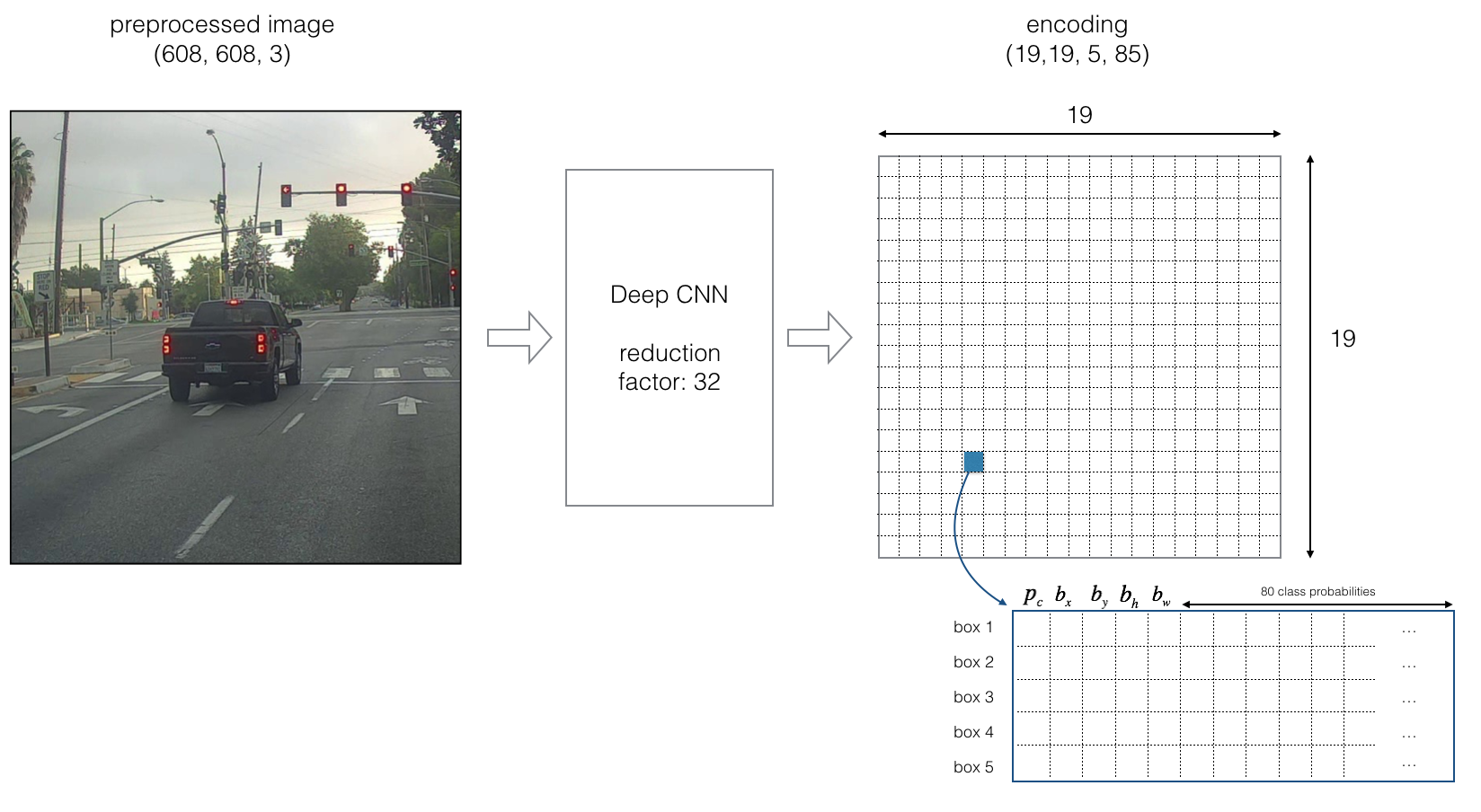
因此,我们将要训练一个端到端的神经网络,输入的shape是(m,608,608,3),输出的shape是(m,19,19,5,85)。这里的m是一次输入的图片数量。我们观察上图可以看到85=80类别+5参数,这5个参数分别代表什么呢?
| 符号 | 意义 |
|---|---|
| pc | 目标网格内有无要检测的目标,取值为[0,1] |
| bx|by | bx 和by确定的是边界框相对于网格单元的中心坐标 |
| bw|bh | bw 和bh确定的是边界框相对于整个图像的宽和高 |
加上这5个参数,我们就能得到边界框的准确位置了。通过下图,我们可以观察这5个参数究竟是如何运作的,能得到什么。
例设这里的box1是我们取神经网络的output[0,0,0,0,:],神经网络判断这个格子里面有要检测的目标,可能性为pc,我们把pc乘上ci就得到了全局的存在可能性{pcci},score=max{pcci}=0.44,查一下数组的索引得到对应的类别是car。

本来
$$
\sum_{i=0}^nc_i=1
$$
$c_i$对应的是以这个格子为系统,各个分类的概率,当我们乘上pc之后, pcci就变成了一个全局的概率,有利于以后不同格子之间的对比。
当我们把这个神经网络训练好了之后,如果不考虑锚框的话,就可以得到下图类似的可视化效果
考虑锚框的话,就得到下图可视化效果

第二步:过滤锚框
- 阈值过滤(thresholding)
经过第一步的分析,每一个锚框都有一个对应的score属性,这个属性在全局是公平的。这一步,我们选定一个阈值排除掉score过于小的锚框,一般可以取0.7,视情况调整。
- 非最大值抑制(Non-max suppression)
有的时候,对于同一辆车,神经网络会给出多个锚框,在这种情况下我们使用非最大值抑制就可以选择出最合适的一个框。
非最大值抑制使用了一个重要指标——交并比(IoU, Intersection over Union),其定义图如下。
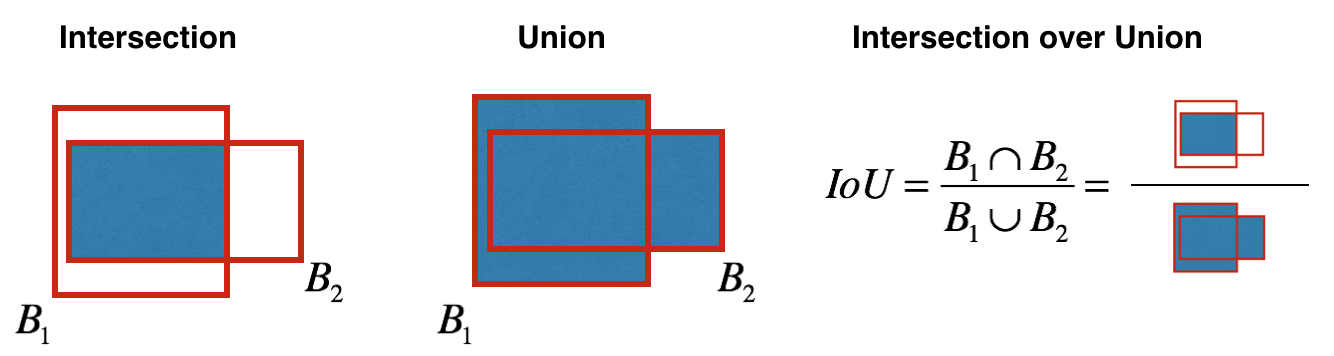
在本例中,给三个锚框按照score降序分别标号为A,B,C, 如果B和C与A的交并比大于一个阈值sigma,就舍弃B,C并保留A;如果B和C与A的交并比均小于阈值sigma,则保留B和C,再对B和C进行非最大值抑制。
第三步:边框回归(Bounding Box Regression)
为什么要进行边框回归呢?因为有的时候神经网络返回的锚框并不准确,如下图红框。因此我们就需要边框回归使得红框拓展为绿框使得边界框变得更加准确。
边框回归的步骤:(详细见参考资料4,我也不太明白)
- 先做平移变换
- 再做尺度缩放
总结
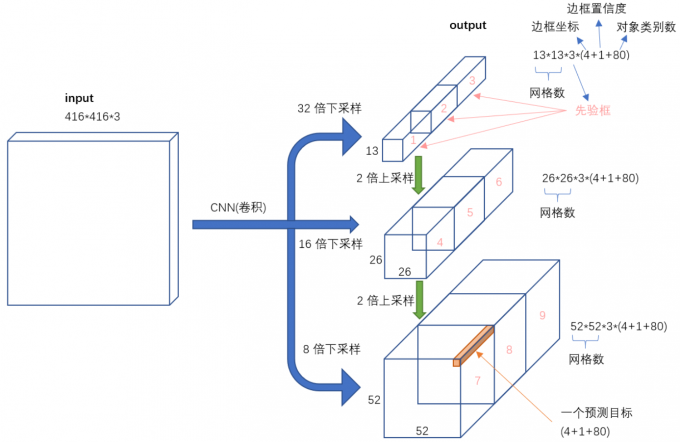
一图以概之:
参考资料:
1、简书:YOLO
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏是不耍流氓的鼓励